Scraping NYC Daycare Data… Again
A year ago, some Civic Hackers in NYC were interested in making a map of New York City Daycare facilities to help parents know what their options were. They were in need of people to scrape the data, as the best official listing of licensed daycare facilities was locked behind a clunky web search interface at the Department of Health and Mental Hygiene’s website. Obeserve:
https://a816-healthpsi.nyc.gov/ChildCare/SearchAction2.do
It’s called Childcare connect, and not only does it give you administrative data about daycare facilities (age range, address, website, years in business, etc), it shows you the results of all of their inspections. This is great, but it’s pretty hard to use, and you need to know the exact name of the facility you want to find, or at least be able to match the name using search. It’s also worth noting that when you choose a day care to view information on, the site does an HTTP POST to the same URL as the search page, so there’s no way to share a link to a daycare’s listing. I also learned that this site only has information for commercial daycare facilities, not home daycares, which are regulated by the State. Why?
I’ve seen lots of government “information portals” like this, where the user is greeted with only a form. The data junkie in me wants to sort columns to see ranges of values, or at least see one listing so I know what kind of information is provided, but this site puts all the work on the user. You need to know exactly what you’re looking for, as there’s no friendly high-level entry point to start drilling down into the information.
A map would be a great way to present the high-level information, as it can immediately give the user a sense of the scale of the data, how many points are there, where are they clustered, etc. Most people can glance at a map and quickly find their home and work locations. With a little styling, we could let the user know either the violation history, age range, or any other facet of the data that would be useful to them.
So the civic hackers I mentioned above needed someone to scrape this data, and I obliged, writing a script in ruby (it was my jam at the time) to programmatically paginate the site above, click each link, and grab the relevant items from the page. They went on to create this map using CartoDB, and even entered it in NYC Big Apps last summer. I can recall behing happy to help, but not caring much about the subject matter. Things change…
Fast forward to 2015, and suddenly daycares and schools are important to me. One of my first projects after starting to work for CartoDB was this map of zoned elementary schools, showing state test scores for each one. I recently went on a daycare visit, and wondered if the inspections data were published, and found myself staring at the childcareconnect website yet again, thinking about how to scrape the violations tables for each daycare.
This time I took a different approach. Instead of writing a scraper that would grab all the data and output it to a CSV, I decided to make a JSON endpoint that scrapes the data “on the fly”. The benefit of this method is that the resulting feed is always as fresh as possible, and there’s no need to run a scheduler to scrape everything all the time. The downside is that I don’t actually retain any of the data, so it’s not aggregated for download and analysis, but that’s ok for now. A bit more code later can do all of that.
Right now I am just interested in providing a JSON endpoint for all violations and details about a daycare facility. The idea is that a user could click on a daycare and trigger a call to this endpoint, which would render all the violations somewhere on the screen.
So here it is. http://daycareproxy.herokuapp.com/id/DC20687 Give it a try. It doesn’t look like much, but it’s unlocking raw data that’s trapped in a website for use elsewhere!
Tech stuff:
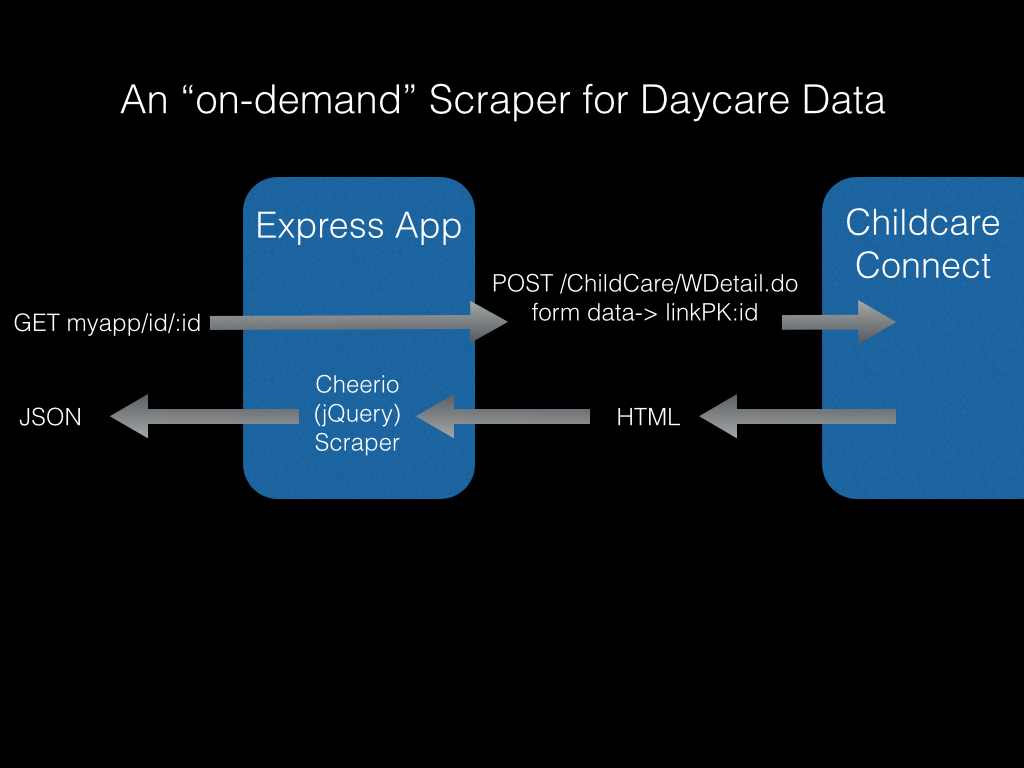
To make this endpoint, I built a simple express.js app in node, with a single endpoint: daycareproxy.herokuapp.com/id/:id
The app takes the :id from the URL path, and does an HTTP POST to load the corresponding page from Childcare Connect.
The response from the NYC server is wrapped in jQuery using the cheerio node package, allowing me to quickly traverse the virtual DOM to find the data points I want.
If you follow the code, you’ll see that each element the scraper is looking for has its own custom chain of jquery find() and children() methods, and probably some string manipulation, trim(), match(), etc.
When the scraper finds its prized data, it’s appended to a data object that will eventually be stringified and sent as the JSON response.
To be continued, when I get around to actually putting this endpoint to use in a web map!
Leave a Reply