Building a Custom Downloader for NYC’s PLUTO Data
I recently launched a custom download tool for NYC’s PLUTO data, which you can check out at http://chriswhong.github.io/plutoplus. Here’s a little bit about how and why I built it:
New York City’s Department of City Planning maintains a geospatial database of tax lots and their associated records that goes by the name of PLUTO (It’s a backronym that stands for Primary Land Use Tax Output). It includes polygons for the city’s 870,000+ tax lots, and over 80 attribute columns including assessments, easements, number of units, number of floors, zoning status, etc. It’s every Urban Planner’s dream dataset, and gives you a treasure trove of information for mapping and analyzing the built environment. PLUTO used to cost money, but is now available as a free download in ESRI Shapefile format from DCP’s time-honored Bytes of the Big Apple website (which pre-dates the Open Data portal and the Open Data law by many years. DCP are the hipsters of Open Data, they were doing it before it was cool).
The downloads consist of a shapefile for each of New York’s 5 boroughs, and range in size from 11MB for Manhattan and 65MB for Queens. Each shapefile contains many thousands of records, and can be quite unruly to work with depending on how much memory you have and what program you’re using. I found myself doing some freelance GIS work recently that involved analyzing a chunk of the city that spanned two boroughs. I ended up having to manually filter down the data from both shapefiles to the areas that I wanted, and then merge the two subsets together so that my study area and all attributes were together in a single file. Then, once I had tamed the geometries, there were 80 columns of attributes, most of which didn’t pertain to my analysis. I only needed 1!
Idea: Build a custom PLUTO downloader that allows the user to select a geographic area and a set of attributes, and get custom PLUTO data on demand.
To accomplish this, the data must live in a spatial database that can take in the parameters for the custom subset of data and return the results quickly over the web. CartoDB is a perfect fit for this problem, and will allow us to send a PostGIS SQL query via its SQL API and get back results in multiple formats.
At the end of the day, this project boils down to a single-page UI that helps the user build a SQL statement for the data they want.
Consolidate the data
The plan was to consolidate the PLUTO geometries for the entire city into a single table, and keep the attributes in a separate table. These two tables would be joined on the fly when the user requests data.
I loaded all 5 PLUTO shapefiles into CartoDB, and stripped them of all of their attribute columns except for BBL (BBL stands for borough, block, & lot and serves as a unique ID that we can use for joins). I then did successive UNIONs, combining them into a single dataset which I named plutoshapes.
I used the full-city non-spatial PLUTO CSV to populate the attributes table, which I named pluto14v2. (PLUTO 2014 version 2… the latest and greatest version) It occurred to me while writing this post that the row counts for these two datasets don’t match, so I’m going to have to figure out why sometime soon.

Make a Simple Visualization in CartoDB
The map used in the frontend will only be for reference purposes, and won’t actually show any data other than the geometries. Creating a CartoDB visualization with a simple SELECT * query and no data-driven styling will allow me to draw PLUTO’s polygons on the frontend’s map with just a few lines of code.
The Frontend
My frontend is a fullscreen map with sidebar, based on this CartoDB Twitter Bootstrap Template I built a while back. I’ll walk through the key functionality of script.js:
First, I set up the page. This involves creating a map using Cartodb’s javascript library, adding a dark basemap to it, then adding the generic PLUTO overlay that I created before.
//initialize map
var map = new L.Map('map', {
center: [40.70663644882689,-73.97815704345703],
zoom: 14
});
//add a basemap
L.tileLayer('https://dnv9my2eseobd.cloudfront.net/v3/cartodb.map-4xtxp73f/{z}/{x}/{y}.png', {
attribution: 'Mapbox Terms & Feedback'
}).addTo(map);
//add cartodb named map
var layerUrl = 'https://cwhong.cartodb.com/api/v2/viz/2602ab80-0353-11e5-89a0-0e0c41326911/viz.json';
cartodb.createLayer(map, layerUrl)
.addTo(map)
.on('done', function(layer) {
}).on('error', function() {
//log the error
});
layerUrl above is a CartoDB viz.json, which is essentially a structured version of the data query and styling rules that went into my generic PLUTO map. If you’re curious, you can load that URL and see what’s inside.
Next, I populate the list of PLUTO attributes from a static JSON file.
//populate fields list
$.getJSON('data/fields.json',function(data) {
//iterate over the results and add each field name to the list in the sidebar
});
I could have retrieved this list of column names using CartoDB’s API and requesting one row of data from the pluto14v2 table, but I wanted to include the descriptions so I ended up making a static csv that I could easily transform into JSON.
Building the Query
With a preview map loaded, and a nice list of attribute columns with checkboxes (and a select all button if the user doesn’t want to scroll through 80 field names), the user can start panning and zooming the map and checking boxes for attributes. All the magic will happen when one of the download buttons is clicked:
$('.download').click(function(){
var data = {};
//get current view, download type, and checked fields
var bbox = map.getBounds();
data.type = $(this).attr('id');
var checked = listChecked();
//generate comma-separated list of fields
data.fields = '';
for(var i=0;i<checked.length;i++) {
if(checked[i]!='bbl') {
data.fields+= checked[i] + ',';
}
}
data.fields=data.fields.slice(0,-1);
data.bboxString = bbox._southWest.lng + ','
+ bbox._southWest.lat + ','
+ bbox._northEast.lng + ','
+ bbox._northEast.lat;
var queryTemplate = 'https://cwhong.cartodb.com/api/v2/sql?skipfields=sbbl,cartodb_id,created_at,updated_at,name,description&format={{type}}&filename=pluto&q=SELECT * FROM plutoshapes a LEFT OUTER JOIN (SELECT bbl,{{fields}} FROM pluto14v2) b ON a.sbbl = b.bbl WHERE ST_INTERSECTS(ST_MakeEnvelope({{bboxString}},4326), a.the_geom)';
var buildquery = Handlebars.compile(queryTemplate);
var url = buildquery(data);
console.log("Downloading " + url);
window.open(url, 'My Download');
});
First, I get the bounding box (lat/lon for the southwest corner of the map & lat/lon for the northeast corner of the map) using leaflet’s .getBounds() method. I then call a function named listChecked() which returns an array of all of the PLUTO attributes that the user checked in the sidebar list.
I’m methodically building out an object named data, which I’ll use with handlebars.js to build out an API call. data.type is the file format the user has requested (based on which button they clicked). data.fields is a string consisting of the user’s selected attributes. data.bboxString is a transformation of the data inside the object returned by .getBounds() that I’ll be able to use in my PostGIS query. Handlebars takes this fully-formed data object and builds out a call to the CartoDB SQL API using this template:
https://cwhong.cartodb.com/api/v2/sql
?skipfields=sbbl,cartodb_id,created_at,updated_at,name,description
&format={{type}}
&filename=pluto
&q=SELECT * FROM plutoshapes a
LEFT OUTER JOIN (
SELECT bbl,{{fields}} FROM pluto14v2
) b ON a.sbbl = b.bbl
WHERE ST_INTERSECTS(ST_MakeEnvelope({{bboxString}},4326), a.the_geom)
https://cwhong.cartodb.com/api/v2/sql is the base SQL API url for my account. skipfields excludes columns from the results (columns that are present in all CartoDB tables but are not relevant to the user). format gets whatever value data.type holds, which will be either “csv”, “shapefile”, or “geojson”. filename simply defines the name of the resulting downloaded file. Finally, q is our SQL query, which I’ll break down below.
Remember, I stored the data in two separate tables, one with all of the geometries, and one with just the attributes. This query is doing a LEFT OUTER JOIN, starting with all of the polygons and then joining them to the attributes where the BBLs match. The comma-separated list of {{fields}} is injected by handlebars.js to specify which columns the user requested from the attributes table. The final WHERE clause contains the bounding box. ST_MAKEENVELOPE() is a PostGIS function that creates a rectangular polygon given a set of bounding box coordinates (which are also injected by handlebars.js as {{bboxString}}) Once the rectangle is defined, I use ST_INTERSECTS to select only those polygons in the PLUTO geometries dataset that are within the box or touching its edges (I could have also used ST_CONTAINS() here, but that would exclude all polygons that are not 100% within the bounding box)
Let’s see it in action. I’ll zoom in on Williamsburg, Brooklyn, and choose only the address, allzoning1, and assessland columns. 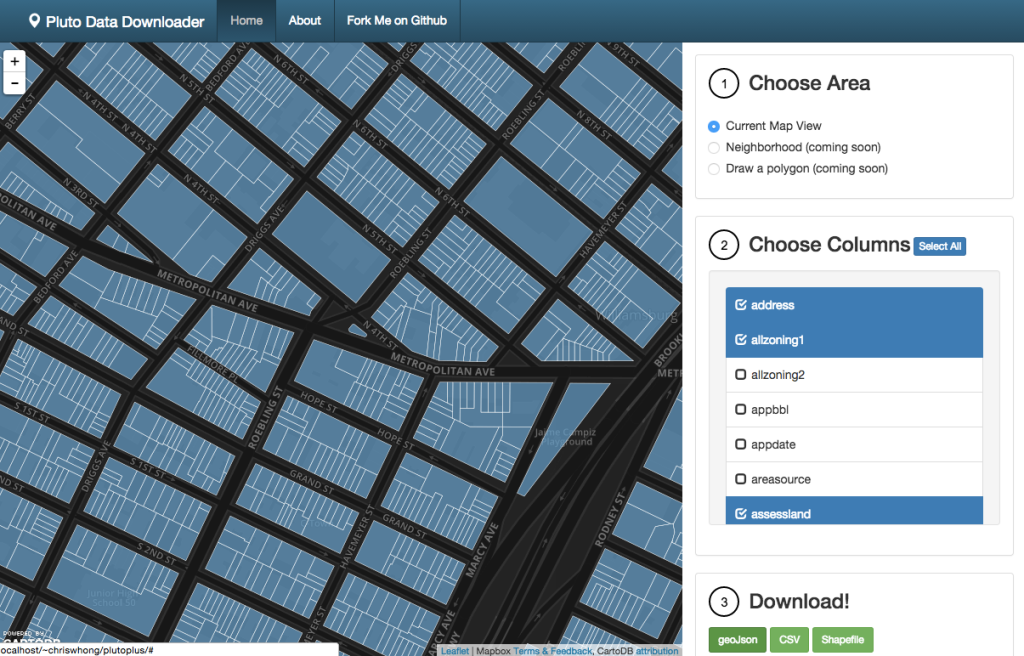 When I click the geojson download button, the following API call is built:
When I click the geojson download button, the following API call is built:
https://cwhong.cartodb.com/api/v2/sql?skipfields=sbbl,cartodb_id,created_at,updated_at,name,description&format=geojson&filename=pluto&q=SELECT * FROM plutoshapes a LEFT OUTER JOIN (SELECT bbl,address,allzoning1,assessland FROM pluto14v2) b ON a.sbbl = b.bbl WHERE ST_INTERSECTS(ST_MakeEnvelope(-73.96154880523682,40.71133720811548,-73.95286917686462,40.71723302006985,4326), a.the_geom)
Compare this to the template and see where handlebars.js did its thing. Now I’ll open the downloaded file in QGIS.

There’s my data, containing only the 903 tax lots that were in my current map view, and only the three columns that I selected (plus BBL, the unique identifier for each polygon)! Woot woot.
So What?
This will be a major time saver for anyone who is uses PLUTO data and finds themselves starting from scratch with the city’s raw shapefiles. It’s also a proof of concept for how governments could better publish large geospatial datasets and I would LOVE to see someone fork this project and stand it up for another dataset in another city.
It turns out that fellow map nut and twitter pal Bill Morris has built a similar custom download tool for Burlington, Vermont, and has written a great blog post about what’s wrong with geo open data portals and why this “few bells and whistles” approach better serves a broad range of data consumers. His version has address search, topojson, and shareable URLs, all things I hope to add if there is any interest from the community.
For now, retrieving data for the current map view is the only option for choosing a specific area, but in the future I will allow the user to draw an arbitrary polygon OR choose a neighborhood, borough, or other relevant NYC geometry to get their data.
Thanks for reading! Support Open Data, and build awesome things!
Leave a Reply