Thoughts on Open Data Part 2
This is part 2 of a blog post containing some of the philosophy on Open Data I’ve developed over the past couple of years (here’s part 1). Here are a couple more tenets:
3) Fooddogging
We often hear the term “dogfooding” in the open data world, which is short for “eating your own dogfood”, the idea that the data that’s released under an Open Data program ought to be good enough for internal consumption by the same government that produced it. If there’s one set of data for using and another set for sharing, you just might be doing it wrong.
The hypothetical workflow behind dogfooding is:
1) Government publishes data
2) Government uses said published data as a source for some kind of analysis/map/other information product.
I hereby coin the term Fooddogging, which reverses this workflow.
1) Government publishes some kind of analysis/map/other information product that used specific sets of data
2) Government publishes the data that was used in #1, links to it from #1, and maintains it as an extension of whatever #1 is.
Projects beget data. Essentially I am advocating for publishing the data that is behind any project that uses data. If you publish a PDF report that has a chart in it that you made in excel, publish the raw data right next to it. If you make a web map and did some useful spatial join or carved up a large dataset into smaller chunks, publish your improved data even if the raw source is already available. Hyperlinking is the new sourcing!
I actually cooked up a web button for linking to your source data. You should use it on your next project. :p

Fooddogging goes hand in hand with “Play it where it lies” from part 1, as open data files will pop up wherever their associated data products do. No fancy software required, just use the web for what it’s good at: moving files from servers to clients.

It’s worth noting that I view what I’m describing here as complimentary to the more deliberate publishing of data under an open data program. Or, if there is no legit open data program in your government, fooddogging is a great way to start releasing data into the wild.
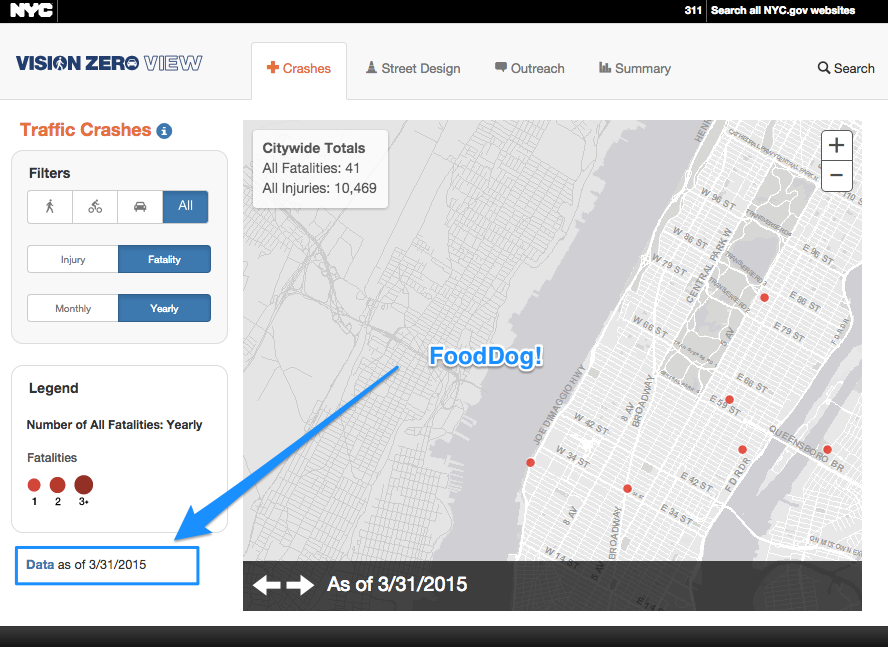
A great example of this is NYC Department of Transportation’s Vision Zero View Map that shows crash locations, street improvements, and outreach activities in support of the DeBlasio Administration’s initiative to reduce pedestrian fatalities.
This map and many others like it have been criticised because they present data that is (or was) not generally available in raw form. However, after some feedback to the developers at DOT by members of the NYC Open Data community, they added a data download page!
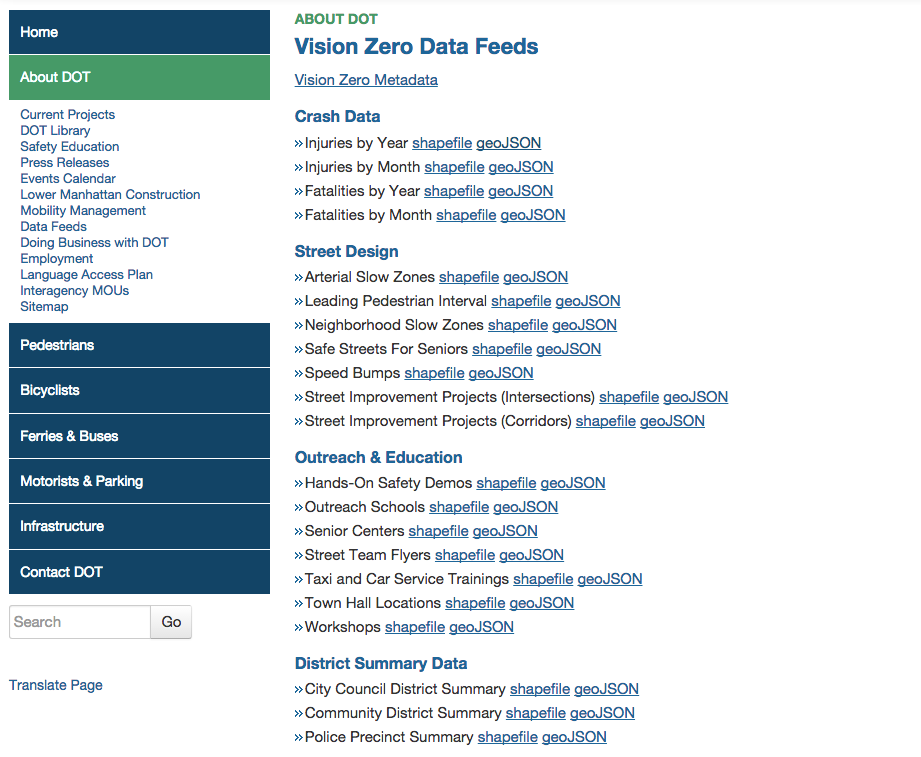
They’ve even provided download links to shapefiles AND geoJSON, giving data consumers an option to use whatever works best.
3.5) Grouping of Datasets is important. The data download page shown above is REALLY simple, but it does something that many open data portals can’t: it gives you a quick list of datasets that are grouped together because they all support a specific initiative. The NYC Open Data Portal has Categories and Tags, but no way to just clump two or three datasets together with their own landing page where some meta-context could be relayed to the consumer. If you happened to land on the “Senior Centers” dataset as listed above, you would have no way of knowing it was 1 of 7 datasets representing vision zero outreach and education.
Some open data portal software actually considers a dataset to be a “set” of data resources, so the ability to create more logical groupings is built right in.
#4 Open Data and Open Source
The great irony of many open data portals is that they are hosted by for-profit proprietary software vendors. It is unfortunate that so many open data programs begin their existence with a procurement instead of a vision. Open Data is too important to be relegated to a line item on a budget.
A recent open source in open data win was data.gov’s adding an “Open With” feature to the datasets on their portal. It almost seems like they want to get you off the portal as quickly as possible so you can start doing something with the data.
Data.gov’s Chief Architect Phil Ashlock explains their reasoning it in a github issue thread:
Much like a typical desktop operating system allows you to choose which application you use to open a certain kind of file, we should enable users to choose which third party service to use to open a dataset on data.gov without needing to download/upload to that service.
And, of course, the code they modified is now free and available for any other CKAN installation to implement. Or not. On top of all that, you and I can jump on that github issue and be a part of the discussion about the feature, whether it is valuable, and how it can be improved. That’s a feedback loop you won’t find with proprietary software vendors, and we should adopt some of these collaborative processes into the open data publishing workflow.
End braindump… that’s all for now. Thanks for reading. I would love to hear thoughts and criticisms, so leave comments below or find me on the twitters.
Leave a Reply